




This post follows our take on the Facebook outage, which you can read here.

Lesson number one: don't assume you're not the smartest person in the room.
The downpour of funnies continues in the various post-mortem chatter of the Facebook et al outage.
This post from the Outages-discussion mailing list may rank pretty high in that deluge:
Sounds similar to "Your geographically diverse fiber paths are no longer
diverse when they enter your building through the same manhole."
It also begs the obvious question: what do "redundant" and "resilient" really mean on implementation?
Over the years, I've always benefited from the (safe) assumption I'm not the smartest person in the room. It means I'm eager to ask sometimes simple questions to smart people, and that my ears perk up for their insights.
When an enormously large technology organization with the best {security,ux,infrastructure,whatever} team in the business puts up a “status.domain.tld” web site, you would think the obvious had been considered.
What is a status page? It's a simple web site alerting users to known outages and service issues with the current systems.
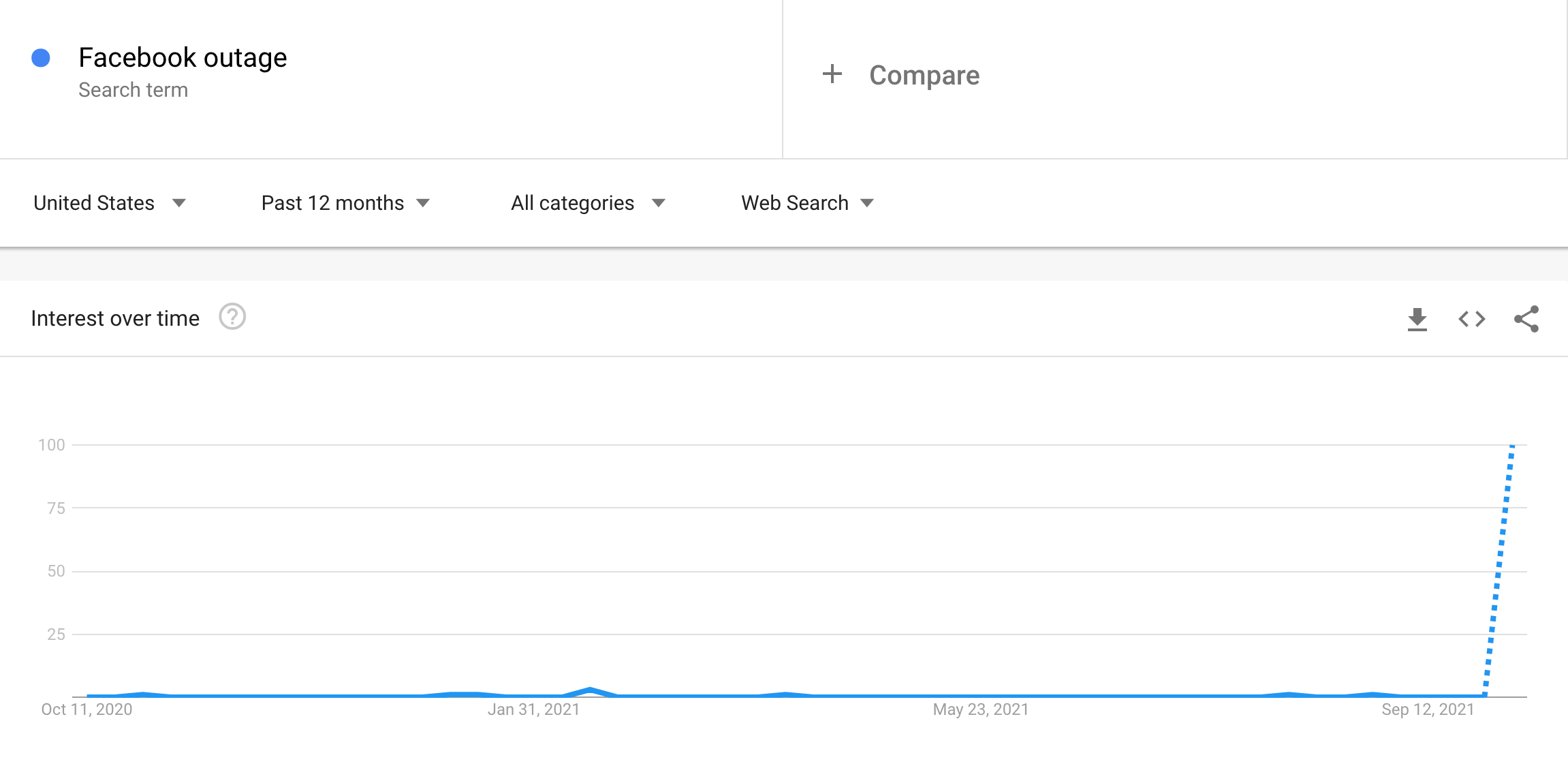
Our colocation facility, New York Internet, for instance, provides an "NYI Status" web site. The last post was on September 2, in regards to Tropical Storm Ida, and it's been quiet for the last month. That's the basic function of a status page. No news is good news, as long as it’s accessible.
Side note for the technically inclined: yes, there’s no 301 redirect to HTTPS for either http://status.nyi.net or http://nyistatus.com from certain user-agents and I have no idea why, but if Phil reads this, I’m sure he’ll sort it out.
Needless to say the entries were dense during Superstorm Sandy in 2012.
But when Facebook faced its seven-hour outage on Monday, why was their status page https://status.fb.com/ also down?
Instead of putting that web site in a completely separate environment distinct from their main systems, Facebook opted for the dumb route of using the same setup as their core web sites. Their BGP apocalypse took down that status page, since it wasn't configured in a separate network environment. For the more technically inclined, that means a separate authoritative DNS, AS, IP block, domain registrar and so on.
Checking today, Facebook took the first step to break up its dangerous monoculture as it opted for Amazon Web Services.
While digging a little deeper with ClearOPS' Service Provider Reports, it becomes immediately clear that I'm still not the dumbest person in the room.
What does whois(1) tell us about the authoritative DNS servers for facebook.com and the status page's domain fb.com?
Name Server: C.NS.FACEBOOK.COMName Server: B.NS.FACEBOOK.COMName Server: A.NS.FACEBOOK.COMName Server: D.NS.FACEBOOK.COMThe domain registrar for both domains is also the same, RegistrarSafe, which again, is wholly part of the Facebook ecosystem. As the simple text on that web page states:
RegistrarSEC, LLC and RegistrarSafe, LLC are ICANN-accredited registrars formed in Delaware and are wholly-owned subsidiaries of Facebook, Inc
Maybe it's different in New York City. Mass outages or even apocalyptic movie scripts have become expected. From 9/11, to the 2003 Northeast electrical grid outage, then again back to Superstorm Sandy in 2012, the "what ifs?" seem entirely possible.
Then again, I was at a meeting in low-lying Red Hook, Brooklyn a few years after it was devastated by Superstorm Sandy in 2012. Someone who had made a big bundle of cash considered putting a data center in the concrete-floored garage of their private residence. What self-respecting sysadmin wouldn't want a data center in their garage, especially in an urban area? Logic overtook excitement fortunately, and I asked if they were in this building during Superstorm Sandy, since that garage was probably a toxic sewage-filled swimming pool for a few weeks. My rhetorical question was to point out that they needed to consider resiliency, which they did.
I don't have any insider information about the logic at play with the Facebook outage. But it's hard not to ask, how does an entity that maintains its own array of data centers and pays exceedingly well for the best and the brightest in technology staff not consider hosting their status page entirely out-of-band from their operations, and outside the reach of any BGP routing table deletions and other sysadmin-themed apocalyptic movie scripts?
There are a lot of difficult and expensive security problems to solve. If you proposed a $5 a month virtual private server-hosted page from some reliable remote provider, written in basic HTML instead of weaving it into the current network, then you could have been the smartest person in some room or another before this past Monday. But then again, you would have also been considered the dumbest person in the room until Monday night.
George is a co-founder and CTO of ClearOPS. By trade, George is a systems administrator out of BSD Unix land, with long-time involvement in privacy-enhancing technologies. By nature, he thrives on creating unorthodox solutions to ordinary problems.
ClearOPS offers knowledge management for privacy and security ops data that is turned into information that can be used to respond to security questionnaires and conduct vendor monitoring. Do you know who your vendors are?